How to Evaluate Assistants#
Python script/notebook for this guide.
Evaluating the robustness and performance of assistants requires careful, reproducible measurement. You can benchmark assistants on a dataset and report metrics. This is what the AssistantEvaluator is designed for.
The AssistantEvaluator works as follows:
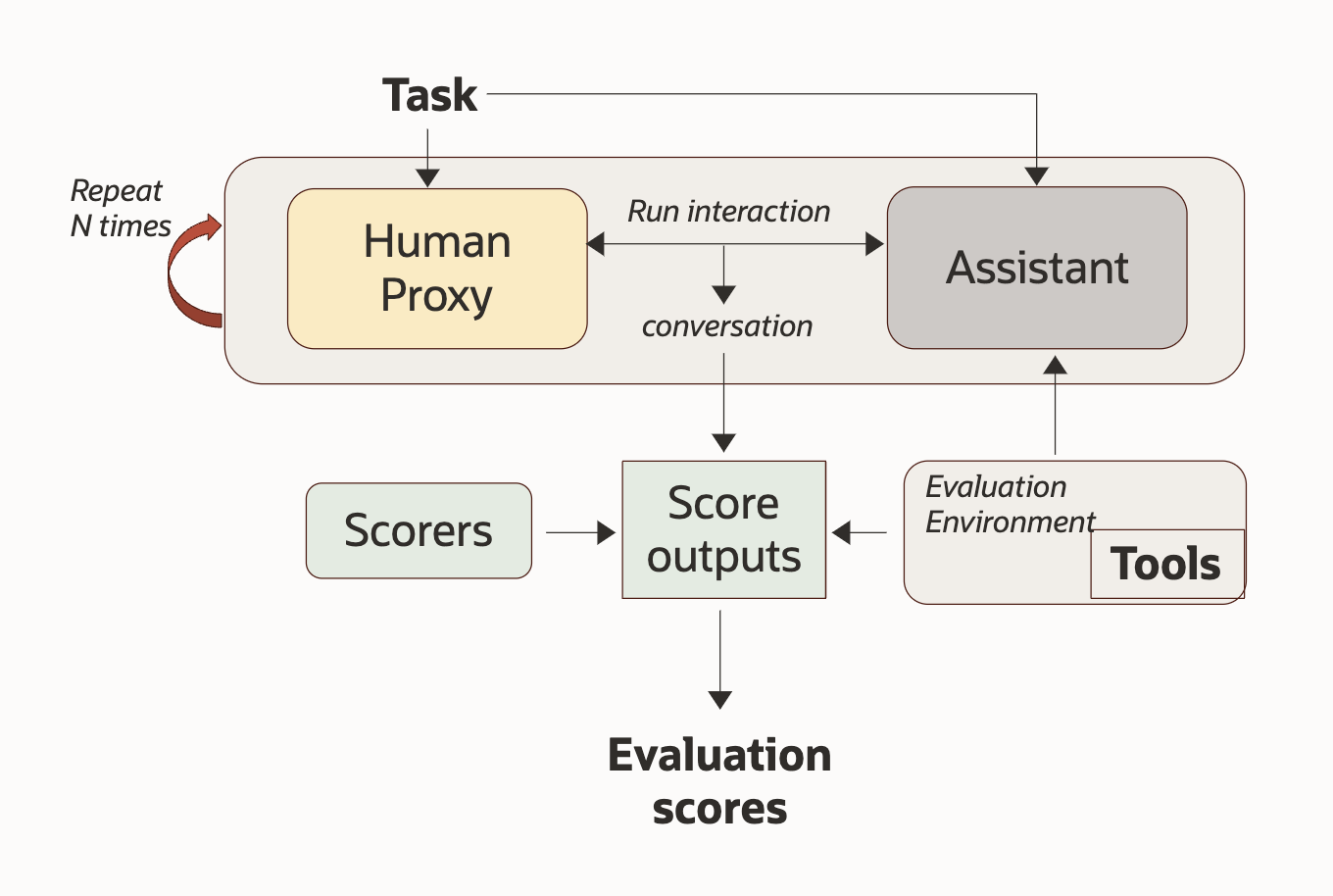
Evaluation is performed by running an AssistantEvaluator over a set of EvaluationTask instances within an EvaluationEnvironment. The environment provides the assistant under test, a human proxy (if needed), and optional lifecycle hooks (init/reset). Metrics are produced by TaskScorer implementations attached to the tasks.
WayFlow supports several LLM API providers. Select an LLM from the options below:
from wayflowcore.models import OCIGenAIModel
if __name__ == "__main__":
llm = OCIGenAIModel(
model_id="provider.model-id",
service_endpoint="https://url-to-service-endpoint.com",
compartment_id="compartment-id",
auth_type="API_KEY",
)
from wayflowcore.models import VllmModel
llm = VllmModel(
model_id="model-id",
host_port="VLLM_HOST_PORT",
)
from wayflowcore.models import OllamaModel
llm = OllamaModel(
model_id="model-id",
)
Basic implementation#
A typical end-to-end evaluation includes:
Defining an evaluation environment that supplies the assistant and (optionally) a human proxy.
Implementing one or more task scorers to compute metrics.
Preparing a set of evaluation tasks (dataset).
Running the evaluator and collecting results.
Define the evaluation environment:
class MathEnvironment(EvaluationEnvironment):
def __init__(self, env_id: str, llm: LlmModel):
self.llm = llm
self.assistant: ConversationalComponent = None
self.human_proxy: HumanProxyAssistant = None
super().__init__(env_id=env_id)
def get_assistant(self, task: EvaluationTask) -> ConversationalComponent:
if self.assistant is not None:
return self.assistant
self.assistant = Agent(
llm=self.llm,
custom_instruction="""The assistant is MathAssistant, tasked with answering math related questions from users.
When asked a question, the assistant should use mathematical reasoning to compute the correct answer. Remember that you have no tool for this job,
so only use your internal computation skills. The output format should be as follows:
Result: [RESULT]""",
)
return self.assistant
def get_human_proxy(self, task: EvaluationTask) -> ConversationalComponent:
if self.human_proxy is not None:
return self.human_proxy
self.human_proxy = HumanProxyAssistant(
llm=self.llm,
full_task_description=task.description,
short_task_description=task.description,
assistant_role="An helpful math assistant, whose job is to answer math related questions involving simple math reasoning.",
user_role="A user having a math-related question. He wants the answer to be formatted in the following format:\nResult: [RESULT]",
)
return self.human_proxy
def init_env(self, task: EvaluationTask):
pass
def reset_env(self, task: EvaluationTask):
pass
math_env = MathEnvironment(env_id="math", llm=llm)
Create a task scorer to compute metrics from the assistant conversation:
class MathScorer(TaskScorer):
OUTPUT_METRICS = ["absolute_error"]
DEFAULT_SCORER_ID = "math_scorer"
def score(
self,
environment: MathEnvironment,
task: EvaluationTask,
assistant: ConversationalComponent,
assistant_conversation: Conversation,
) -> Dict[str, float]:
last_assistant_message = assistant_conversation.get_last_message().content.lower()
if "result:" not in last_assistant_message:
raise ValueError("Incorrect output formatting")
assistant_answer = last_assistant_message.split("result:")[-1]
assistant_answer = assistant_answer.split("\n")[0].replace("$", "").strip()
assistant_answer = float(assistant_answer)
expected_answer = task.scoring_kwargs["expected_output"]
error = abs(expected_answer - assistant_answer)
return {"absolute_error": error}
def score_exceptional_case(
self,
environment: MathEnvironment,
exception: Exception,
task: EvaluationTask,
assistant: ConversationalComponent,
assistant_conversation: Conversation,
) -> Dict[str, float]:
return {"absolute_error": None}
scorers = [MathScorer(scorer_id="benefit_scorer1")]
Prepare the evaluation configuration (dataset and tasks):
data = [
{
"query": "What is the answer to the question: 2+2 = ?",
"expected_output": 4,
},
{
"query": "What is the answer to the question: 2x2 = ?",
"expected_output": 4,
},
{
"query": "What is the answer to the question: 2-2 = ?",
"expected_output": 0,
},
{
"query": "What is the answer to the question: 2/2 = ?",
"expected_output": 1,
},
]
tasks = [
EvaluationTask(
task_id=f"task_{i}",
description=question["query"],
scorers=scorers,
scoring_kwargs={"expected_output": question["expected_output"]},
)
for i, question in enumerate(data)
]
Run the evaluation and inspect the results:
evaluator = AssistantEvaluator(
environment=math_env,
max_conversation_rounds=1,
)
results = evaluator.run_benchmark(tasks, N=1)
print(results)
# task_id task_attempt_number absolute_error conversation
# 0 task_0 0 0.0 [Message(content='...
# 1 task_1 0 0.0 [Message(content='...
# 2 task_2 0 0.0 [Message(content='...
# 3 task_3 0 0.0 [Message(content='...
Hint
Task kwargs vs Scoring kwargs
Use task kwargs to parameterize task execution (information the assistant needs).
Use scoring kwargs to store ground truth and other scoring parameters.
Important
Task scorers must extend TaskScorer and follow its API. See the API docs for details.
Next steps#
Having learned how to evaluate WayFlow Assistants end-to-end, you can proceed to:
How to Create Conditional Transitions in Flows to branch out depending on the agent’s response.
Full code#
Click on the card at the top of this page to download the full code for this guide or copy the code below.
1# Copyright © 2025 Oracle and/or its affiliates.
2#
3# This software is under the Universal Permissive License
4# %%[markdown]
5# WayFlow Code Example - How to Evaluate Assistants
6# -------------------------------------------------
7
8# How to use:
9# Create a new Python virtual environment and install the latest WayFlow version.
10# ```bash
11# python -m venv venv-wayflowcore
12# source venv-wayflowcore/bin/activate
13# pip install --upgrade pip
14# pip install "wayflowcore==26.1"
15# ```
16
17# You can now run the script
18# 1. As a Python file:
19# ```bash
20# python howto_evaluation.py
21# ```
22# 2. As a Notebook (in VSCode):
23# When viewing the file,
24# - press the keys Ctrl + Enter to run the selected cell
25# - or Shift + Enter to run the selected cell and move to the cell below# (UPL) 1.0 (LICENSE-UPL or https://oss.oracle.com/licenses/upl) or Apache License
26# 2.0 (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0), at your option.
27
28# .. imports:
29from typing import Dict
30
31from wayflowcore.agent import Agent
32from wayflowcore.conversation import Conversation
33from wayflowcore.conversationalcomponent import ConversationalComponent
34from wayflowcore.models.llmmodel import LlmModel
35from wayflowcore.evaluation import (
36 AssistantEvaluator,
37 EvaluationEnvironment,
38 EvaluationTask,
39 TaskScorer,
40 HumanProxyAssistant,
41)
42
43
44# %%[markdown]
45## Define the llm
46
47# %%
48from wayflowcore.models import VllmModel
49
50llm = VllmModel(
51 model_id="LLAMA_MODEL_ID",
52 host_port="LLAMA_API_URL",
53)
54
55
56
57# %%[markdown]
58## Define the environment
59
60# %%
61class MathEnvironment(EvaluationEnvironment):
62 def __init__(self, env_id: str, llm: LlmModel):
63 self.llm = llm
64 self.assistant: ConversationalComponent = None
65 self.human_proxy: HumanProxyAssistant = None
66 super().__init__(env_id=env_id)
67
68 def get_assistant(self, task: EvaluationTask) -> ConversationalComponent:
69 if self.assistant is not None:
70 return self.assistant
71
72 self.assistant = Agent(
73 llm=self.llm,
74 custom_instruction="""The assistant is MathAssistant, tasked with answering math related questions from users.
75When asked a question, the assistant should use mathematical reasoning to compute the correct answer. Remember that you have no tool for this job,
76so only use your internal computation skills. The output format should be as follows:
77Result: [RESULT]""",
78 )
79 return self.assistant
80
81 def get_human_proxy(self, task: EvaluationTask) -> ConversationalComponent:
82 if self.human_proxy is not None:
83 return self.human_proxy
84 self.human_proxy = HumanProxyAssistant(
85 llm=self.llm,
86 full_task_description=task.description,
87 short_task_description=task.description,
88 assistant_role="An helpful math assistant, whose job is to answer math related questions involving simple math reasoning.",
89 user_role="A user having a math-related question. He wants the answer to be formatted in the following format:\nResult: [RESULT]",
90 )
91 return self.human_proxy
92
93 def init_env(self, task: EvaluationTask):
94 pass
95
96 def reset_env(self, task: EvaluationTask):
97 pass
98
99
100math_env = MathEnvironment(env_id="math", llm=llm)
101
102
103
104# %%[markdown]
105## Define the scorer
106
107# %%
108class MathScorer(TaskScorer):
109 OUTPUT_METRICS = ["absolute_error"]
110 DEFAULT_SCORER_ID = "math_scorer"
111
112 def score(
113 self,
114 environment: MathEnvironment,
115 task: EvaluationTask,
116 assistant: ConversationalComponent,
117 assistant_conversation: Conversation,
118 ) -> Dict[str, float]:
119 last_assistant_message = assistant_conversation.get_last_message().content.lower()
120 if "result:" not in last_assistant_message:
121 raise ValueError("Incorrect output formatting")
122 assistant_answer = last_assistant_message.split("result:")[-1]
123 assistant_answer = assistant_answer.split("\n")[0].replace("$", "").strip()
124 assistant_answer = float(assistant_answer)
125 expected_answer = task.scoring_kwargs["expected_output"]
126 error = abs(expected_answer - assistant_answer)
127 return {"absolute_error": error}
128
129 def score_exceptional_case(
130 self,
131 environment: MathEnvironment,
132 exception: Exception,
133 task: EvaluationTask,
134 assistant: ConversationalComponent,
135 assistant_conversation: Conversation,
136 ) -> Dict[str, float]:
137 return {"absolute_error": None}
138
139
140scorers = [MathScorer(scorer_id="benefit_scorer1")]
141
142
143# %%[markdown]
144## Define the evaluation config
145
146# %%
147data = [
148 {
149 "query": "What is the answer to the question: 2+2 = ?",
150 "expected_output": 4,
151 },
152 {
153 "query": "What is the answer to the question: 2x2 = ?",
154 "expected_output": 4,
155 },
156 {
157 "query": "What is the answer to the question: 2-2 = ?",
158 "expected_output": 0,
159 },
160 {
161 "query": "What is the answer to the question: 2/2 = ?",
162 "expected_output": 1,
163 },
164]
165tasks = [
166 EvaluationTask(
167 task_id=f"task_{i}",
168 description=question["query"],
169 scorers=scorers,
170 scoring_kwargs={"expected_output": question["expected_output"]},
171 )
172 for i, question in enumerate(data)
173]
174
175# tasks = []
176
177# %%[markdown]
178## Run the evaluation
179
180# %%
181evaluator = AssistantEvaluator(
182 environment=math_env,
183 max_conversation_rounds=1,
184)
185results = evaluator.run_benchmark(tasks, N=1)
186print(results)
187# task_id task_attempt_number absolute_error conversation
188# 0 task_0 0 0.0 [Message(content='...
189# 1 task_1 0 0.0 [Message(content='...
190# 2 task_2 0 0.0 [Message(content='...
191# 3 task_3 0 0.0 [Message(content='...