
Monitor traffic flows with a Service mesh
Self guided student - video introduction
This video is an introduction to the monitoring traffic with a Service mesh lab. Depending on your browser settings it may open in this tab / window or open a new one. Once you've watched it please return to this page to continue the labs.
[](https://youtu.be/sLOM1FUcPwE "Using the service mesh to monitor traffic introduction video")
---
Introduction
This is one of the optional sets of Kubernetes labs
Estimated module duration 20 mins.
Objectives
This module shows how to use Linkerd to see the traffic flows between your microservices.
Prerequisites
You need to complete the Rolling update module (last of the core Kubernetes labs modules). You must have completed the Installing the Linkerd service mesh module. You can have done any of the other optional module sets, or any combination of the other service mesh modules.
Task 1: Using the service mesh to see what’s happening
We’ve seen how to install and run the service mesh, we’re now doing to look at how to use it.
Task 1a: Starting a load generator
The first thing we need is some load so we can see what the service mesh is doing, there is a load generator script we can use to do this
Change to the directory for the service mesh scripts
- In the OCI Cloud shell type
<copy>cd $HOME/helidon-kubernetes/service-mesh</copy>
Once you are in the directory start the load generator
If your cloud shell session is new or has been restarted then the shell variable $EXTERNAL_IP may be invalid, expand this section if you think this may be the case to check and reset it if needed.
How to check if $EXTERNAL_IP is set, and re-set it if it's not
**To check if `$EXTERNAL_IP` is set**
If you want to check if the variable is still set type `echo $EXTERNAL_IP` if it returns the IP address you're ready to go, if not then you'll need to re-set it, there are a couple of ways to do this, expand the appropriate section below.
If you used the automated scripts in the kubernetes-lab directory to setup the microservices in Kubernetes
- Open the OCI cloud shell
The automated scripts will create a script file `$HOME/clusterSettings.one` this can be executed using the shell built in `source` to set the EXTERNAL_IP variable for you.
```bash
source $HOME/clusterSettings.one
```
```
EXTERNAL_IP set to 139.185.45.98
NAMESPACE set to tg
```
Of course the actual IP address and namespace will almost certainly be different from the example here !
---
If you manually setup the Kubernetes ingress services using helm
In this case as you manually set this up you will need to get the information from Kubernetes itself
- Open the OCI cloud shell
- You are going to get the value of the `EXTERNAL_IP` for your environment. This is used to identify the DNS name used by an incoming connection. In the OCI cloud shell type
```bash
kubectl get services -n ingress-nginx
```
```
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.182.204 130.162.40.241 80:31834/TCP,443:31118/TCP 2h
ingress-nginx-controller-admission ClusterIP 10.96.216.33 443/TCP 2h
```
- Look for the `ingress-nginx-controller` line and note the IP address in the `EXTERNAL-IP` column, in this case that's `130.162.40.121` but it's almost certain that the IP address you have will differ. IMPORTANT, be sure to use the IP in the `EXTERNAL-IP` column, ignore anything that looks like an IP address in any other column as those are internal to the OKE cluster and not used externally.
- In the OCI Cloud shell type the following, replacing `[external ip]` with the IP address you retrieved above.
```bash
export EXTERNAL_IP=[external ip]
```
---
</details>
</details>
2. In the OCI Cloud shell type
```bash
bash generate-service-mesh-load.sh $EXTERNAL_IP 2
```
```
Iteration 1
Iteration 2
....
```
This will continue generating the load making a request roughly every 2 seconds.
If you get a DNS error that `store.2.nip.io` (or similar) cannot be found this means that `EXTERNAL_IP` is not set, follow the instructions above to set it and then re-run the curl command.
Note, the OCI Cloud Shell session will terminate (and thus kill off the load generator) after 20 minutes of inactivity. If this happens you will see the throughput figures for your namespace and services in the Linkerd and Grafana UI's drop to zero and potentially even disappear if they fall outside the time ranges displayed.
If that happens while you are doing the service mesh labs the solution is to connect back to the OCI CLoud shell and restart the load generator
### Task 1b: Viewing the load
1. In your laptop web browser go to `https://linkerd..nip.io` (replace `` with that of your load balancer)
You may be challenged as you have a self signed certificate. Follow the normal procedures in your browser to accept the connection and proceed.
Next you may be presented with the login challenge.
2. If you are login with `admin` as the username, for the password use the one you used when creating the login password during the linkerd installation in the previous module.
You'll be presented with the linkerd-web main page, unlike when you saw this previously now it's showing load for your services.
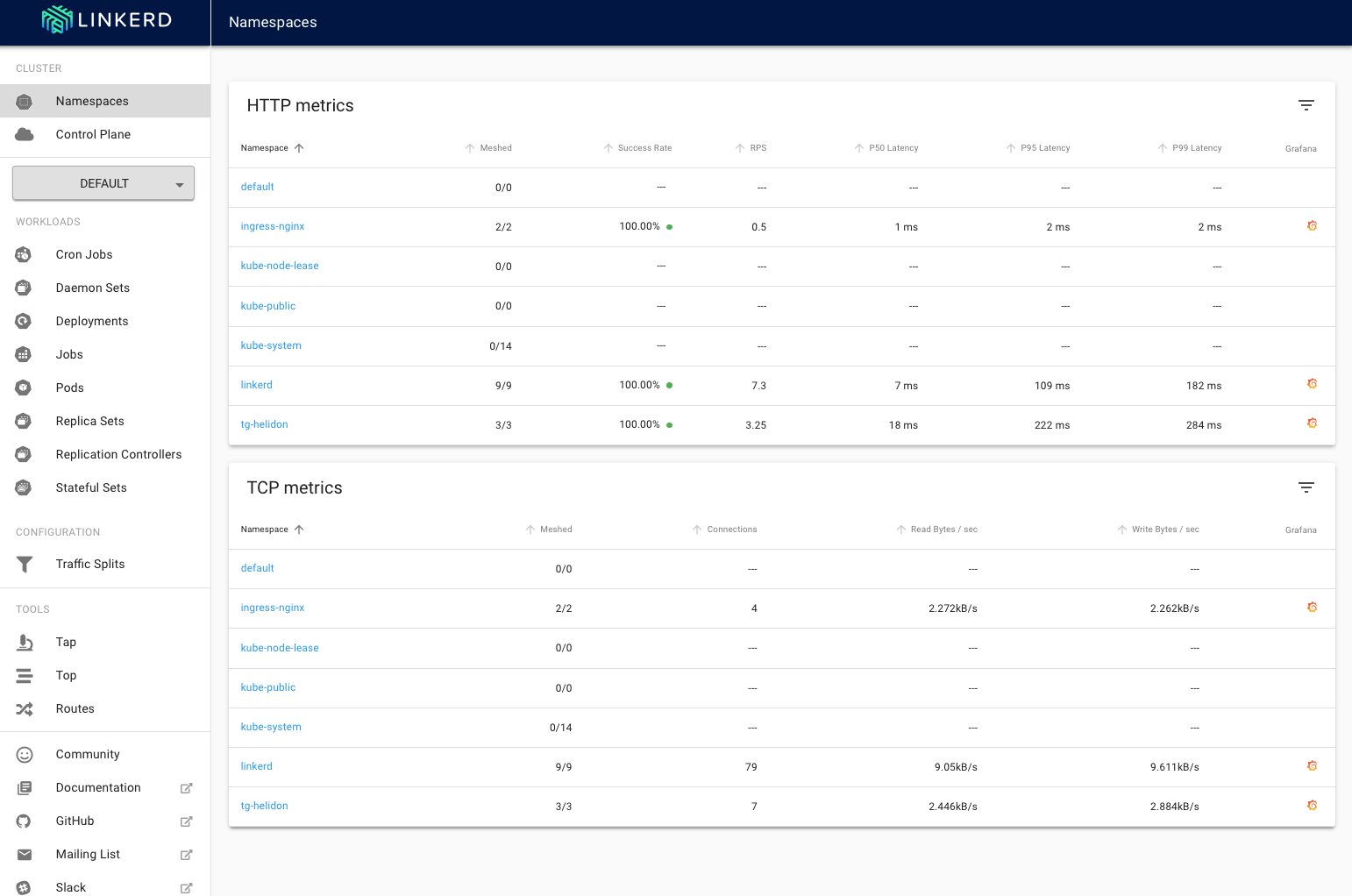
You can see that in both the HTTP metrics and TCP metrics sections the namespace tg-hekidon (your namespace will be different of course) is showing a request rate.
Unlike the Kubernetes dashboard the linkerd UI is very much about providing you with data about what's happening. The data is captured by the linkerd-proxies that form the data plane of the service mesh and then made available via the Promtheus implementation the linkerd install process created. The UI doesn't really offer options for configuring linkerd
A key point here is that this UI is showing you the **current** load (well actually data collated and processed over the very recent history. To see historical data we can use the Grafana instance that the linkerd install process setup. We'll get to that later in the module, for now we're just going to look at the Linkerd UI
What are the column headings?
Note, Clicking on a column name will cause the data in the table to be sorted by that column in ascending order, this is useful for example if you had a lot of namespaces to quickly see which ones had the most traffic or failures. Clicking on the column name a second time will change the sort order to be descending.
In the HTTP Metrics section the columns are :
`Namespace` - The name of the namespace
`Meshed` - the number of deployments in the namespace that are part of the service mesh, in this case it's all of the ones in your namespace and the ingress-nginx namespace, but it is possible that in some cases a deployment may not be included (perhaps a deployment has not been restarted, or a deployment has annotations that explicitly disable the use of the service mesh)
`Success Rate` - How often a request made by a deployment within the namespace succeeds, this can be the start of diagnosing problems
`RPS` - The number of requests per second
`P50 Latency` - The maximum time taken to respond to for the fastest 50% of requests.
`P95 Latency` - The maximum time taken to respond to for the fastest 95% of requests.
`P99 Latency` - The maximum time taken to respond to for the fastest 99% of requests.
`Grafana` - If the namespace is in the mesh a little Garafana logo will appear here, clicking on it will switch to the Grafana UI showing the HTTP details for the namespace. **Don't do this now**, we'll look at it later on
In the TCP Metrics section the columns are :
`Namespace` - The name of the namespace
`Meshed` - the number of deployments in the namespace that are part of the service mesh
`Connections` - The number of active connections (I believe this has some averaging applied)
`Read Bytes/sec` and `Write Bytes/sec` - The data volumes being written and read in the namespace
`Grafana` - If the namespace is in the mesh a little Garafana logo will appear here
---
How to exclude a service from the service mesh ?
Once a namespace has the `linkerd.io/inject: enabled` annotation set then all deployments (and thus app pods) started in the namespace will be detected by the linkerd control plane and the linkerd-proxy (and init) containers will be automatically injected without you having to do anything. This allows you to easily use linkerd in situations where you're using a deployment tool (e.g. helm) and not have to modify the helm charts yourself.
To prevent this from happening simply add the annotation `linkerd.io/inject: disabled` to the pod / deployment, then when the service starts the linkerd control plane will know not to setup the linkerd-proxy and init containers for that pod / pods in the deployment.
---
What about the database connection ?
There are a couple of points here. Firstly we are looking at HTTP data. It's quite probable that the connection which JDBC uses to actually talk to the database is not HTTP based, so we wouldn't expect it to show up in an HTTP report.
But even it we were looking at the TCP metrics report we still wouldn't see the connections from the stockmanager to the database. This is because the database exists outside the service mesh (and the entire Kubernetes cluster) So though the service mesh can see the TCP connection being setup there is no service mesh at the "other" end to receive the connection, thus it will not be able to generate the metrics data as it just doesn't have the information.
Of course if the database was implemented as a Kubernetes based service (perhaps we were using MySQL in the cluster as our database) then the connection from the stock manager to the database would show up if we had enabled linkerd on the pods in that deployment.
---
What happens if the control plane fails ?
Obviously if the service mesh is managing all of the network traffic flowing in your cluster then there's a concern as to what will happen if the service mesh itself fails.
The details below cover Linkerd but the basic principles apply to all service meshes.
Firstly the control plane is itself running in Kubernetes, this means if the control plans services have problems then the containers will be restarted automatically by Kubernetes, equally upgrades can be done in a rolling manner.
If the control plane does have a significant failure then existing proxies (i.e. for existing pods) will continue to operate, though they won't get any updates to their configuration until the control plane comes back. Of course any new pods will not get their configuration, so will not be able to communicate (though they should get the additional proxy containers configured in the pods for when the control plane becomes available.)
In summary - what you have working will continue to work, but making changes will not be effective until the control plane restarts.
There is more information on control plan failure in [the linkerd FAQ](https://linkerd.io/2/faq/#what-happens-to-linkerds-proxies-if-the-control-plane-is-down)
---