
Setup Log capture for Processing
Self guided student - video introduction
This video is an introduction to the Log Capture for processing labs Depending on your browser settings it may open in this tab / window or open a new one. Once you've watched it please return to this page to continue the labs.
[](https://youtu.be/QjvhjL0hxLE "Kubernetes log capture for procesing video")
---
Introduction
This is one of the optional sets of Kubernetes labs. This lab currently uses a slightly older version of Elastic Search as the data store, it will soon be updated to use the open source Open Search.
Please be aware that this log capture works if you are using manually managed nodes, for virtual nodes you will need a different approach as they don’t support daemon sets. The approach described here is one of several approaches and this focused on handling the log data capture within Kubernetes, OKE also supports ways of directly capturing log data using OCI log management techniques as well
Estimated module duration 20 mins.
Objectives
This module shows how to install and configure the log capture tool Fluentd, and write data to an elastic search instance where it could be subsequently processed or analyzed (the actual processing / analysis is not covered in this module)
Task 1: Log capture for processing and analysis
Developers create log entries for a reason, but as we’ve seen so far they are not that easy to get at in Kubernetes.
The problem with log data in a distributed cloud native environment
Many applications generate log data, in the case of Java programs this is usually achieved by a logging library, in the case of the Helidon parts of the labs we have used the Simple Logging Facade (The @slf4j Lombok annotation in the code) which allows us to easily switch the actuall logging engine being used. Other languages also have their own logging frameworks, for example in Ruby there is the Logger class, and in there are open source libraries like log4c.
Most Unix (and Linux) systems provide support for syslogd which enables system operations as well as code to generate log messages.
The problem is that the output of the log messages is not always consistent, for example syslogd writes it's data to a system directory and most code logging frameworks have many different output mechanisms including files, the system console, and also standard output.
To make things even more complicated there are many different output formats, plain ASCII is common, but json, xml are often used. Even something as simple as the date / time is often specified by the authors of the code itself and is in their local format (it's rare to see a log event using seconds / milliseconds as per Unix / Java time)
All of these options make logging complicated, where to capture the data and what it looks like make it very difficult to have consistent logging, and given that micro-service based architectures are often deployed using micro-services from many locations and in many programming languages this is a problem.
Fortunately the 12 factors has a [simple recommendation on logging](https://12factor.net/logs) that addresses at least some of these problems. The recommendation is that logs should be treated as a stream of data being sent to the applications standard out, and that the rest of the process is a problem for the execution environment.
As part of its design Kubernetes does save all the information sent by a pod to its standard out, and we have seen this when we look at the logs for a pod, we did this earlier on when we used the dashboard to have a log at the logs, and also the command `kubectl logs -n ` let's us see the logs (use `-f` to "follow" the log as new information is added)
This is good, but with in a distributed architecture a single request may (almost certainly will) be processed by multiple individual micro-services. We've seen how zipkin can be used to generate trace data as a request traverses multiple micro-services, but how can integrate the log data ?
---
</details>
If your cloud shell session is new or has been restarted then the shell variable `$EXTERNAL_IP` may be invalid, expand this section if you think this may be the case to check and reset it if needed.
How to check if $EXTERNAL_IP is set, and re-set it if it's not
**To check if `$EXTERNAL_IP` is set**
If you want to check if the variable is still set type `echo $EXTERNAL_IP` if it returns the IP address you're ready to go, if not then you'll need to re-set it, there are a couple of ways to do this, expand the appropriate section below.
If you used the automated scripts in the kubernetes-lab directory to setup the microservices in Kubernetes
- Open the OCI cloud shell
The automated scripts will create a script file `$HOME/clusterSettings.one` this can be executed using the shell built in `source` to set the EXTERNAL_IP variable for you.
```bash
source $HOME/clusterSettings.one
```
```
EXTERNAL_IP set to 139.185.45.98
NAMESPACE set to tg
```
Of course the actual IP address and namespace will almost certainly be different from the example here !
---
If you manually setup the Kubernetes ingress services using helm
In this case as you manually set this up you will need to get the information from Kubernetes itself
- Open the OCI cloud shell
- You are going to get the value of the `EXTERNAL_IP` for your environment. This is used to identify the DNS name used by an incoming connection. In the OCI cloud shell type
```bash
kubectl get services -n ingress-nginx
```
```
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.182.204 130.162.40.241 80:31834/TCP,443:31118/TCP 2h
ingress-nginx-controller-admission ClusterIP 10.96.216.33 443/TCP 2h
```
- Look for the `ingress-nginx-controller` line and note the IP address in the `EXTERNAL-IP` column, in this case that's `130.162.40.121` but it's almost certain that the IP address you have will differ. IMPORTANT, be sure to use the IP in the `EXTERNAL-IP` column, ignore anything that looks like an IP address in any other column as those are internal to the OKE cluster and not used externally.
- IN the OCI CLoud shell type the following, replacing `[external ip]` with the IP address you retrieved above.
```bash
export EXTERNAL_IP=[external ip]
```
---
</details>
</details>
## Task 2: Setting up Elastic search
To process log data in a consistent manner we need to get all of the data into one place. We're going to use [fluentd](https://www.fluentd.org/) to capture the data and send it to an Elastic search instance deployed in our Kubernetes cluster in the initial example below, but there are many other options.
### Task 2a: Configuring the environment for the elastic search install
As with elsewhere in the labs we'll do this module in it's own namespace, so first we have to create one.
1. In the cloud console type
```bash
kubectl create namespace logging
```
```
namespace/logging created
```
Now let's use helm to install the elastic search engine into the logging namespace
2. First add the Elastic helm chart repository.
```bash
helm repo add elastic https://helm.elastic.co
```
```
"elastic" has been added to your repositories
```
3. Update the repository cache
```bash
helm repo update
```
```
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "ingress-nginx" chart repository
...Successfully got an update from the "kubernetes-dashboard" chart repository
...Successfully got an update from the "elastic" chart repository
Update Complete. ⎈ Happy Helming!⎈
```
4. Make sure you are in the right environment which holds the yaml files
```bash
cd $HOME/helidon-kubernetes/management/logging
```
### Task 2b: Setting up the security for the elastic search install
The default configuration for the elastic service does not have any password protection. For demo purposes this might be OK, but we **are** on the internet and so should use something more secure (and of course you **must** use a strong password in a production environment!)
First let's create a password file for the admin user. In the example below I'm using `ZaphodBeeblebrox` as the password, but please feel free to change this if you like
1. In the OCI Cloud Shell type
```bash
htpasswd -c -b auth admin ZaphodBeeblebrox
```
```
Adding password for user admin
```
Now having create the password file we need to add it to Kuberntes as a secret so the ingress controller can use it.
2. In the OCI Cloud Shell type
```bash
kubectl create secret generic web-ingress-auth -n logging --from-file=auth
```
```
secret/web-ingress-auth created
```
3. Let's create the certificate for this service. In the OCI cloud shell type the following.
```bash
$HOME/keys/step certificate create search.logging.$EXTERNAL_LP.nip.io tls-search-$EXTERNAL_IP.crt tls-search-$EXTERNAL_IP.key --profile leaf --not-after 8760h --no-password --insecure --kty=RSA --ca $HOME/keys/root.crt --ca-key $HOME/keys/root.key
```
```
Your certificate has been saved in tls-search-123.456.789.123.crt.
Your private key has been saved in tls-search-123.456.789.123.key.
```
(The above is example output, your files will be based on the IP you provided)
If your output says it's created key files like `tls-search.crt` and does not include the IP address then the `EXTERNAL_IP` variable is not set, please follow the instructions in Task 1 and re-run the step certificate creation command
4. Create the tls secret from the certificate. In the OCI cloud shell type the following., as usual you must replace `` with the IP address of the ingress controller
```bash
kubectl create secret tls tls-search --key tls-search-$EXTERNAL_IP.key --cert tls-search-$EXTERNAL_IP.crt -n logging
```
```
secret/tls-search created
```
### Task 2c: Installing elastic search
1. Now we can actually install elastic search. In the cloud console type the following.
```bash
helm install elasticsearch elastic/elasticsearch --namespace logging --version 8.5.1 --set ingress.enabled=true --set ingress.tls[0].hosts[0]="search.logging.$EXTERNAL_IP.nip.io" --set ingress.tls[0].secretName=tls-search --set ingress.hosts[0].host="search.logging.$EXTERNAL_IP.nip.io" --set ingress.hosts[0].paths[0].path='/' --set ingress.annotations."nginx\.ingress\.kubernetes\.io/auth-type"=basic --set ingress.annotations."nginx\.ingress\.kubernetes\.io/auth-secret"=web-ingress-auth --set ingress.annotations."nginx\.ingress\.kubernetes\.io/auth-realm"="Authentication Required"
```
```
NAME: elasticsearch
LAST DEPLOYED: Wed Jul 21 13:16:34 2021
NAMESPACE: logging
STATUS: deployed
REVISION: 1
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=logging -l app=elasticsearch-master -w
2. Test cluster health using Helm test.
$ helm test elasticsearch
```
There are a lot of options in this command, this is because the elastic search helm stack is written slightly differently from some of the others we've used so far (it doesn't have a single "Set up an ingress" option) so we need to define the ingress host and tls details more precisely. Additionally to protect thge actuall elastic search service we are also specifying the annotations to make the ingress controller ask for a security password.
Let's check on the installation, note that is can take a few mins for the elastic search to be loaded and installed.
2. In the cloud console type
```bash
kubectl get all -n logging
```
```
NAME READY STATUS RESTARTS AGE
pod/elasticsearch-master-0 1/1 Running 0 4m57s
pod/elasticsearch-master-1 1/1 Running 0 4m57s
pod/elasticsearch-master-2 0/1 Pending 0 4m57s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch-master ClusterIP 10.96.76.71 9200/TCP,9300/TCP 4m58s
service/elasticsearch-master-headless ClusterIP None 9200/TCP,9300/TCP 4m58s
NAME READY AGE
statefulset.apps/elasticsearch-master 2/3 4m58s
```
3. We can check that the software has been installed by using the helm test command. In the OCI cloud shell type
```bash
helm test elasticsearch -n logging
```
```
Pod elasticsearch-qepig-test pending
Pod elasticsearch-qepig-test pending
Pod elasticsearch-qepig-test pending
Pod elasticsearch-qepig-test succeeded
NAME: elasticsearch
LAST DEPLOYED: Wed Jul 21 13:16:34 2021
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: elasticsearch-qepig-test
Last Started: Wed Jul 21 13:24:23 2021
Last Completed: Wed Jul 21 13:24:25 2021
Phase: Succeeded
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=logging -l app=elasticsearch-master -w
2. Test cluster health using Helm test.
$ helm test elasticsearch
```
### Task 2d: Accessing the service
1. In a web browser go to the web page `https://search.logging..nip.io/_cat` (replace `External IP>` with your ingress controller IP address) If you get a 503 or 502 error this means that the elastic search service is still starting up. Wait a short time then retry.
2. If needed in the browser, accept a self signed certificate. The mechanism varies by browser and version, but as of September 2020 the following worked with the most recent (then) browser version.
- In Safari you will be presented with a page saying "This Connection Is Not Private" Click the "Show details" button, then you will see a link titled `visit this website` click that, then click the `Visit Website` button on the confirmation pop-up. To update the security settings you may need to enter a password, use Touch ID or confirm using your Apple Watch.
- In Firefox once the security risk page is displayed click on the "Advanced" button, then on the "Accept Risk and Continue" button
- In Chrome once the "Your connection is not private" page is displayed click the advanced button, then you may see a link titled `Proceed to ....(unsafe)` click that.
We have had reports that some versions of Chrome will not allow you to override the page like this, for Chrome 83 at least one solution is to click in the browser window and type the words `thisisunsafe` (copy and past doesn't seem to work, you need to actually type it). Alternatively use a different browser.
3. When prompted enter the username of `admin` and the password you chose when you setup the credentials (we suggested `ZaphodBeeblebrox` but if you chose your own you'll need to use that).
We can see that the elastic search service is up and running, let's see what data it holds
4. In a web browser go to `http:///_cat/indices` (remember to substitute **your** external IP address) look at the indices in the service
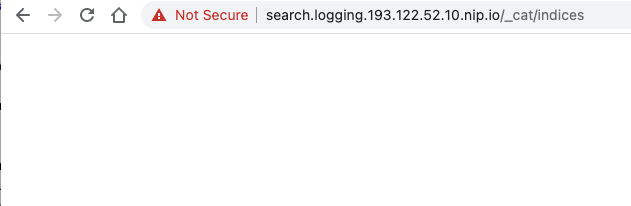
Well, it's empty! Of course that shouldn't be a surprise, we've not put any log data in it yet!
### Task 2e: Capturing the log data from the micro-services
Kubernetes writes the log data it captures to files on the host that's running the node. To get the data we therefore need to run a program on every node that accesses the log files and sends them to the storage (elastic search in this case)
So far we've just asked Kubernetes to create deployments / replica sets / pods and it's determined the node they will run based on the best balance of availability and resources, how do we ensure that we can run a service in each node ?
Well the daemonset in Kubernetes allows the definition of a pod that will run on every node in the cluster, we just have to define the daemonset and the template of the pod that's going to do the work and Kubernetes will deal with the rest, ensuring that even if nodes are added or removed that a pod matching the daemonset definition is running on the node.
Other benefits of using daemon sets
The daemon set is a separate pod, running with it's own set of resources, thus while it does consume resources at the node and cluster level it doesn't impact the performance of the pods it's extracting log data for.
Additionally the daemon set can look at the log data for all of the pods in the node, if we did the logging within a pod (say by replacing the log processor or your micro-service) then you'd have to modify every pod, but by logging it to standard out and using a deamonset you can capture the data of all of the logs at the same time, and only need to make changes in a single place.
---