Self guided student - video introduction Introduction
This is one of the optional sets of Kubernetes labs
Estimated module duration 20 mins.
Objectives
This module shows how to install and configure the log capture tool Fluentd, and write data to the Oracle Object Storage service archive for long term retention of the log data.
Prerequisites
You need to complete the Rolling update module (last of the core Kubernetes labs modules). You can have done any of the other optional module sets. The log capture for processing module is also optional.
Please be aware that this log capture works if you are using manually managed nodes, for virtual nodes you will need a different approach as they don’t support daemon sets. The approach described here is one of several approaches and this focused on handling the log data capture within Kubernetes, OKE also supports ways of directly capturing log data using OCI log management techniques as well
Task 1: Capturing data to archive it
The problem with log data in a distributed cloud native environment -n ` let's us see the logs (use `-f` to "follow" the log as new information is added)
This is good, but with in a distributed architecture a single request may (almost certainly will) be processed by multiple individual micro-services. We've seen how zipkin can be used to generate trace data as a request traverses multiple micro-services, but how can integrate the log data ?
---
</details>
Sometimes you want to save log data in the longer term, possibly for legal reasons. While the initial part of the process is similar the approach used for capturing log data for processing the storage structure needed for long term storage of data is usually very different from that needed for the analysis of the data. This is especially true if the chance is high that the data will not ever be used ("Write Only Data") where you need to meet the obligations to store it, but are focused on the costs or saving and storing, and the cost of a very occasional retrieval is less important. For example it may be considered very reasonable to not index log data that is in being held for long term storage, but only group it in large chunks, say one chunk per day) understanding that if data is needed that the entire days data may need to be processed, but accepting the cost of doing that as it's less than the overhead of creating and maintaining an index with a higher resolution.
We're going to now look at how to extract data and save it to a storage service. This section is based on [this blog entry created by Ankit Bansal](http://www.ankitbansal.net/centralized-logging-in-oracle-kubernetes-engine-with-object-storage/#) but modified to fit in with the specific environment of the lab and to split the configuration of the storage from the fluentd basic configuration.
Note, if you have the fluentd configuration setup monitoring to Elastic Search you can leave that running if you like. It is of course consuming resources, but there are situations where you may want long term storage of log data as well as short term analytics.
## Task 2: Create the logging namespace
If you did not do the capture log for processing, or deleted the logging namespace at the end of that module you will need to create a namespace for this module.
As with elsewhere in the labs we do this module in it's own namespace.
1. In the cloud console type
```bash
kubectl create namespace logging
```
```
namespace/logging created
```
If the namespace already exists this command will report : `Error from server (AlreadyExists): namespaces "logging" already exists`
## Task 3: Storing the log data
Kubernetes writes the log data it captures to files on the host that's running the node. To get the data we therefore need to run a program on every node that accesses the log files and sends them to the storage.
So far we've just asked Kubernetes to create deployments / replica sets / pods and it's determined the node they will run based on the best balance of availability and resources, how do we ensure that we can run a service in each node ?
Well the daemonset in Kubernetes allows the definition of a pod that will run on every node in the cluster, we just have to define the daemonset and the template of the pod that's going to do the work and Kubernetes will deal with the rest, ensuring that even if nodes are added or removed that a pod matching the daemonset definition is running on the node.
Other benefits of using daemon sets .compat.objectstorage..oraclecloud.com` Obviously we need to determine the value of `` (you have just retrieved the region identifier)
5. In the upper right of the screen you can access your tenancy details.

6. Click on the little "shadow" of a person to access your profile.
7. Click on the tenancy name (oractdemeabdnmative in this case) to access the tenancy details
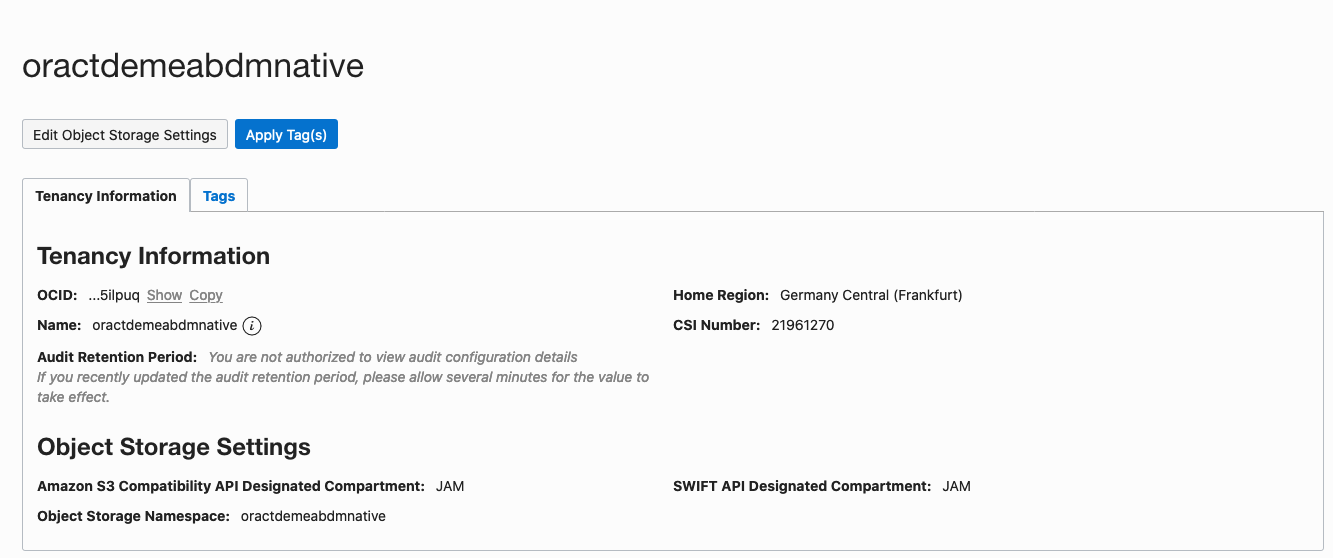
In this case in the Object Storage Settings you can see that the `Object Storage Namespace` is `oractdemeabdmnative` It will be different in other tenancies. This particular tenancy is quite old which is why the storage namespace is the same as the tenancy name, recent tenancies have a storage namespace that is a set of random letters and numbers.
The object storage endpoint is `https://.compat.objectstorage..oraclecloud.com` Replace `` with the value you've just retrieved and `` with the value you gathered earlier.
For example **FOR MY TENANCY, YOURS WILL VARY** it might be `https://oractdemeabdmnative.compat.objectstorage.eu-frankfurt-1.oraclecloud.com`
8. Save the Object Storage Service endpoint in your texteditor for later use.
9. Note the value for the `Amazon S3 Compatibility API Designated Compartment:` (`JAM` in this case)
This is the OCI compartment that will be used to hold the storage bucket. In this case the compartment is named `JAM` If there is no compartment shown then the storage bucket will be created in the root compartment. If you want to change that (only do this if this is your tenancy, if it belongs to your organization then make sure your tenancy admin is OK with you changing it as you might break other things) then click the `Edit Object Storage Settings` and chose another compartment (if this is a new tenancy you may only have the root compartment).
**Important** You need to have rights to create storage objects in the compatibility compartment, If this is a trial tenancy then you will be operating as the tenancy administrator, if it's a commercial tenancy you may need to check with your admins to ensure you have the appropriate rights.
We need to have security keys to access the S3 compliant storage API. Access those from the User details.
10. Click on the little "shadow" of a person to access your profile.

11. Click on your name (in this case oracleidentitycloudservice/tim.graves) to go to your account details.
12. Locate the resources section, this is on the lower left of the page (you may need to scroll down to see it

13. Click on the **Customer Secret Keys** in the resources section.
The table changes to showing the **Customer Secret Keys** table
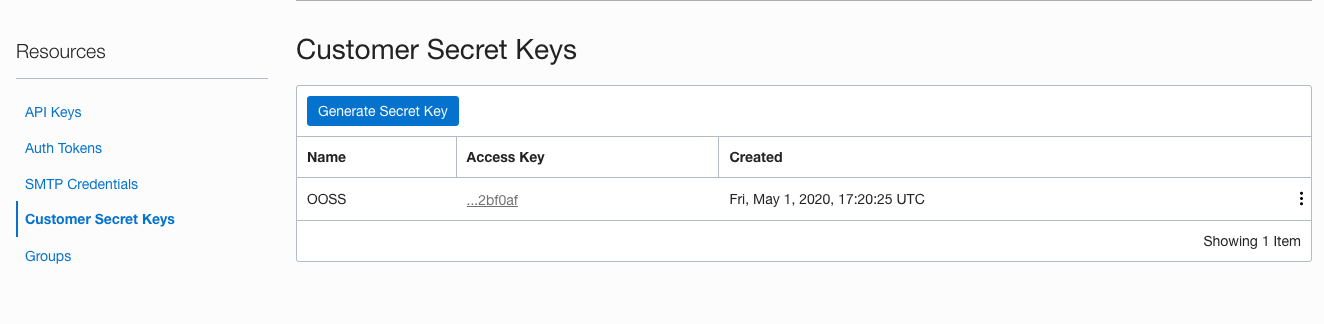
In this case there is already one Customer secret key for my account.
Note, if you have already generated a Customer Secret Key for another reason (you may have been doing a different lab) and you still have both the key and the secret, then you can re-use those values. You only need to do this if you do not have the information for a secret key you've previously generated.
To generate a new Customer Secret Key
14. Click the generate secret key button.
15. Provide a name that you'll be able to remember, in this case I'm using `MySecretKey` but you chose your own
16. Click the **Generate Secret Key** button, to get the system to generate a key pair for you.
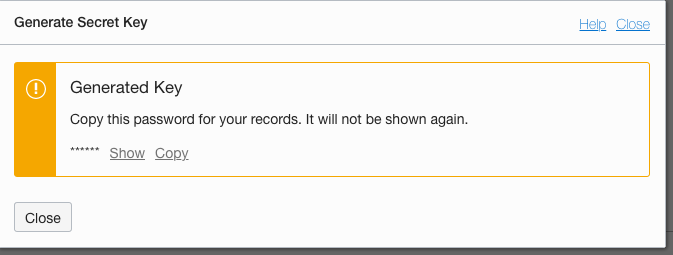
**VITALLY IMPORTANT**
17. Click the **Copy** link to copy the secret key, be sure to paste it into a texteditor or somewhere safe (this is a secret key, so it needs to be protected against access). **You cannot retrieve it at any point once this popup is closed**
18. **ONLY** after you'ce copied and saved the secret key click the **Close** button
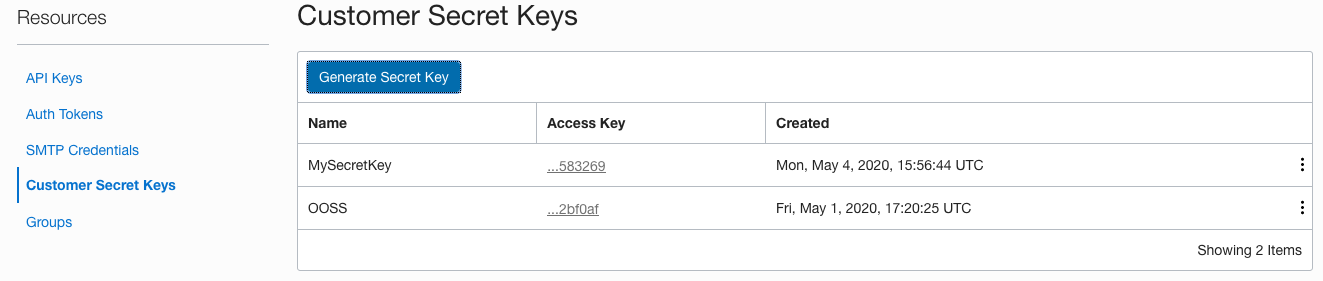
You'll see the newly generated key in the list (remember in this case I had an existing key, you may not have in which case you'll only see the key you just generated)
You now need to get the access key (this is the other part of the generated key pair)
19. Click on the **Access key** for the key you just generated, if you have multiple keys remember to chose the key you just generated (the name you chose will help you)
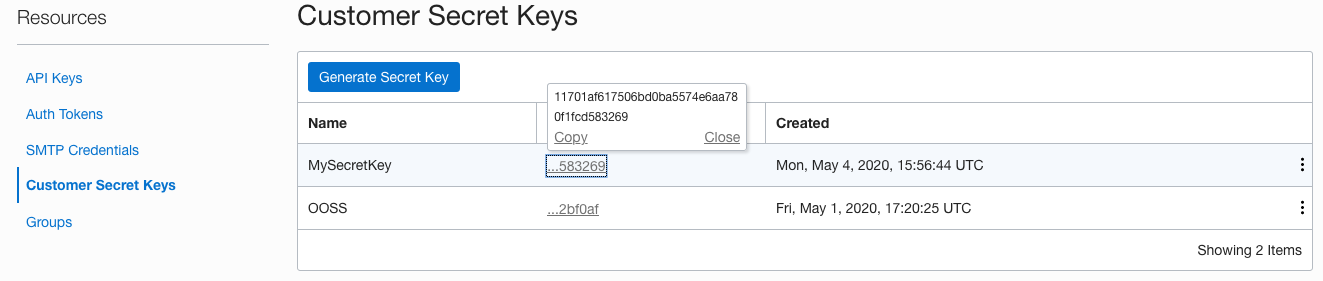
20. Click on the **Copy** link to get a copy of the key, save this in a text editor or something.
You have now gathered the information we need to write data into the Object Storage Service.
### Task 3b: Create the storage bucket to hold the logs
You can let the S3 integration just create the storage bucket, but the scenario we are looking at here is for the long term retention of the log data for occasional access, in that case you want the cheapest possible storage, and for that you need the archive storage tier for the storage bucket. This is not the default tier so it needs to be set when the Oracle Object Storage Service bucket is created. The archive tier does mean that there is a delay to retrieve the data (Archive after all is about long term efficient storage of the data) so if you were planning on doing something with the data directly (For example uploading into the Oracle log analytics service) as you'd be transferring them once they were uploaded to the storage service, and probably only retaining them for a short while after that you would use the standard tier.
What's the difference between Standard and Archive tiers? -FLUENTD` For fluentd to write to this bucket the name **must** be entirely in UPPER CASE and you **must** replace with something unique to you!
6. Change the storage tier option to **archive**
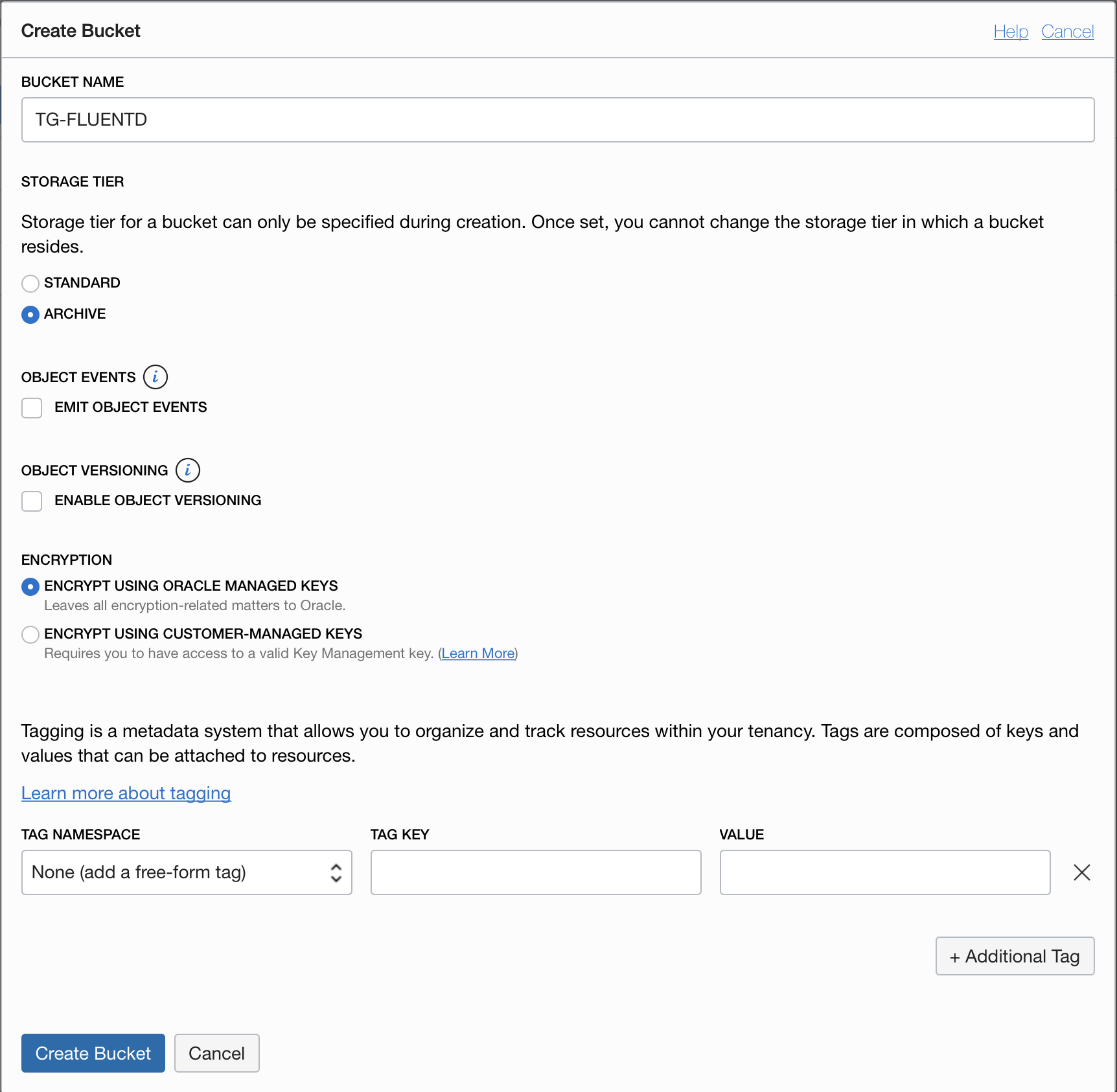
7. Click the **Create Bucket** button
Note, if the bucket name must be unique across your entire tenancy in the region, if it's not (even if the other bucket is in a different compartment) you will not be able to create it and will have to try again using a different name.
You will now see the list of buckets in your compartment. Remember that in my case the `TG` bucket existed previously, so there are two shown here.
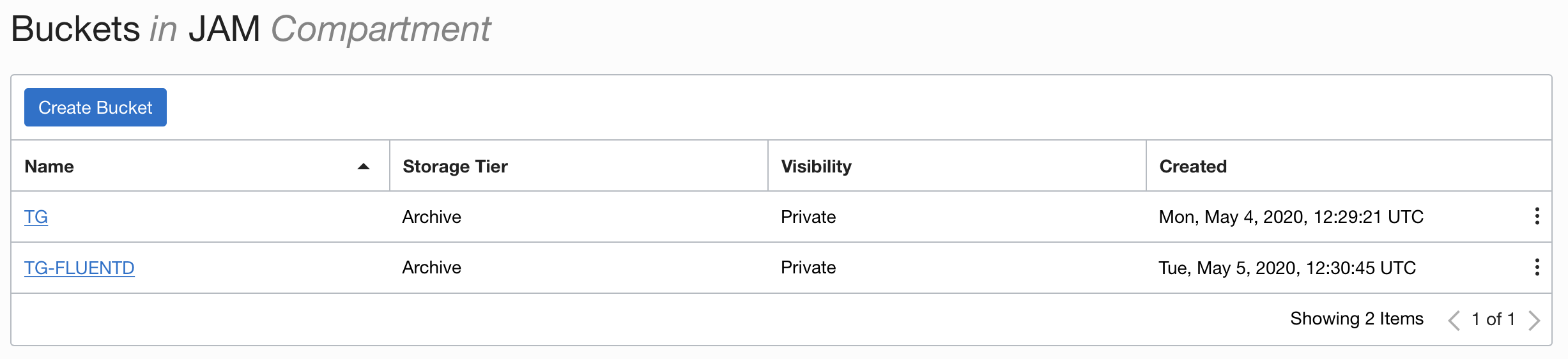
Note that the storage tier for the new bucket (named TG-FLUENTD in this case **but yours will vary**) is **Archive** This means all data will be held in a long term storage model which is much cheaper, but may take time to become available when requested.
### Task 3c: Configuring the log monitoring process.
1. In the OCI Cloud shell Change to the logging folder.
```bash
cd $HOME/helidon-kubernetes/management/logging
```
There are a several of yaml files that we will use. These will all be applied in the `logging` namespace
The `fluentd-to-ooss-configmap.yaml` file defines a configuration map representing the basic configuration for fluentd, in this case it tells it to use the S3 compatible output for all log data. This is mounted into the pod as the the `fluentd.conf` file. This config map brings in some of the environment variables that are defined in the `fluentd-s3-configmap` and processed when the `fluentd-daemonset-oss-rbac.yaml` is applied and the logs start. Kubernetes uses the syntax `"#{ENV['SWITCH_LOG_FILE_INTERVAL']}"` to identify that the environment variable needs to be substituted.
The `fluentd-s3-configmap.yaml` contains a config map with the specific settings we will be using (these are what you gathered above) which are applied to the environment variables inside the pod. You will need to edit this to hold the values you gathered.
The `fluentd-daemonset-oss-rbac.yaml` configures the cluster role, service account, binding between the two and also the details of the daemonset that gathers the log data and writes it to the S3 compatible storage service. The daemon set uses the values that are set in the `fluentd-s3-configmap.yaml` for it's environment variables (look at the file for the details of how the environment variables are defined in terms of config map entries). This means we won't need to change the daemon set configuration / it's yaml file if we want to change those settings.
Using Kubernetes 1.20 or earlier ? How does Kubernetes know where to get the environment variable values ? vi fluentd-s3-configmap.yaml
```
Remember to keep the values in double quotes.
- ACCESS_KEY - This is the OCI access key
- ACCESS_SECRET - This is the OCI secret key
- REGION - The OCI Region
- STORAGE_END_POINT - The object storage endpoint
- BUCKET_NAME - The name of the bucket you created
Do not change the ROTATION_INTERVAL setting, leave that set to 60
The following is an **example** of the updated file. This specific example **will not work** in your tenancy, you will need to use the values you gathered for your tenancy.
```yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-s3-config
namespace: logging
data:
ACCESS_KEY: "225c7ab16d07465e1234567e724863ea552e11b0"
ACCESS_SECRET: "bgUdGT20T4KpFh5awJR0pZBwxR4siml2utj3f+W2mJ8="
BUCKET_NAME: "TG-FLUENTD"
REGION: "eu-frankfurt-1"
STORAGE_END_POINT: "https://oractdemeabdmnative.compat.objectstorage.eu-frankfurt-1.oraclecloud.com"
SWITCH_LOG_FILE_INTERVAL: "60"
```
What's the SWITCH_LOG_FILE_INTERVAL for? kubectl apply -f fluentd-to-ooss-configmap.yaml
```
```
configmap/fluentd-config-to-ooss configured
```
Why didn't I need to specify a namespace ? kubectl apply -f fluentd-s3-configmap.yaml
```
```
configmap/fluentd-s3-config configured
```
Finally let's start the daemonset itself
3. In the OCI Cloud Shell type
```bash
kubectl apply -f fluentd-daemonset-ooss-rbac.yaml
```
```
serviceaccount/fluentd-to-ooss created
clusterrole.rbac.authorization.k8s.io/fluentd-to-ooss created
clusterrolebinding.rbac.authorization.k8s.io/fluentd-to-ooss created
daemonset.apps/fluentd-to-ooss created
```
Let's make sure that everything has started
4. In the OCI Cloud Shell type
```bash
kubectl get daemonsets -n logging
```
```
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd-to-ooss 2 2 2 2 2 88s
```
We can see that there are 2 instances running, this is because the cluster I am using has 2 nodes, and Kubernetes will ensure that there is a pod for each daemonset running on each node (restarting it on the same node if the pod crashes)
Let's get the specifics of the pods
5. In the OCI Cloud Shell type
```bash
kubectl get pods -n logging
```
```
NAME READY STATUS RESTARTS AGE
fluentd-to-ooss-fgx4s 1/1 Running 0 55s
fluentd-to-ooss-frkrp 1/1 Running 0 55s
```
In this case I had left the fluentd and elastic search instances running from the log capture for processing module running. This is why you can see a total of 6 fluentd pods running, three (fluentd-to-es) writing to Elastic Search (whcih itself has a number of pods) and three (fluentd-to-ooss) writing to Oracle Object Storage Service. If you have not done the log capture for processing lab (or tidies up after it) then you should only see three fluend based pods.
What's with the CrashLoopBackOff STATUS ?
time_key "time"
tag_key "tag"
localtime false
@type "file"
path "/var/log/fluentd-buffers/s3.buffer"
timekey 60
timekey_use_utc true
chunk_limit_size 256m
</match>
2020-05-05 14:53:37 +0000 [info]: starting fluentd-1.10.2 pid=6 ruby="2.6.6"
2020-05-05 14:53:37 +0000 [info]: spawn command to main: cmdline=["/usr/local/bin/ruby", "-Eascii-8bit:ascii-8bit", "/fluentd/vendor/bundle/ruby/2.6.0/bin/fluentd", "-c", "/fluentd/etc/override/fluent.conf", "-p", "/fluentd/plugins", "--gemfile", "/fluentd/Gemfile", "--under-supervisor"]
2020-05-05 14:53:37 +0000 [info]: adding match in @FLUENT_LOG pattern="fluent.**" type="null"
2020-05-05 14:53:37 +0000 [info]: adding filter pattern="kubernetes.**" type="kubernetes_metadata"
2020-05-05 14:53:38 +0000 [info]: adding match pattern="**" type="s3"
2020-05-05 14:53:38 +0000 [info]: adding source type="prometheus"
2020-05-05 14:53:38 +0000 [info]: adding source type="prometheus_output_monitor"
2020-05-05 14:53:38 +0000 [info]: adding source type="tail"
...
more adding source stuff
...
2020-05-05 14:53:38 +0000 [info]: adding source type="tail"
2020-05-05 14:53:38 +0000 [info]: #0 starting fluentd worker pid=15 ppid=6 worker=0
2020-05-05 14:53:38 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/kube-flannel-ds-kbphm_kube-system_install-cni-95d15a83f2fc30c51a4467c7e8314cdd442c62e430d61f31f6dfa9cb72e5836e.log
2020-05-05 14:53:38 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/kube-proxy-mx5cq_kube-system_kube-proxy-92ac482f6ee8ab963ec3660877efc007e75f967a46a7a3e6514f0fb961e2fc93.log
2020-05-05 14:53:38 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/kube-flannel-ds-kbphm_kube-system_kube-flannel-f2bc3614d3e7079f83a75ace155a42be641243320b5f9ca088ecd6961b739279.log
2020-05-05 14:53:38 +0000 [info]: #0 [in_tail_container_logs] following tail of /var/log/containers/proxymux-client-t5m64_kube-system_proxymux-client-821a69cbc98bccf181260fc184fc5172ef5487812098eafffa1b269a7e3572e0.log
...
Lots more output
...
```
The log data shows is the sources whish fluentd is scanning looking for the log data, The match section is the contents of the config map we specified in `fluentd-to-ooss-configmap.yaml` but note that there are values for items like `s3-bucket` which reflect the settings we provided in the `fluentd-s3-configmap.yaml` file of our environment specific settings.
If the log is reporting an unexpected error How to check if $EXTERNAL_IP is set, and re-set it if it's not If you used the automated scripts in the kubernetes-lab directory to setup the microservices in Kubernetes source $HOME/clusterSettings.one
```
```
EXTERNAL_IP set to 139.185.45.98
NAMESPACE set to tg
```
Of course the actual IP address and namespace will almost certainly be different from the example here !
---
If you manually setup the Kubernetes ingress services using helm kubectl get services -n ingress-nginx
```
```
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.182.204 130.162.40.241 80:31834/TCP,443:31118/TCP 2h
ingress-nginx-controller-admission ClusterIP 10.96.216.33 443/TCP 2h
```
- Look for the `ingress-nginx-controller` line and note the IP address in the `EXTERNAL-IP` column, in this case that's `130.162.40.121` but it's almost certain that the IP address you have will differ. IMPORTANT, be sure to use the IP in the `EXTERNAL-IP` column, ignore anything that looks like an IP address in any other column as those are internal to the OKE cluster and not used externally.
- IN the OCI CLoud shell type the following, replacing `[external ip]` with the IP address you retrieved above.
```bash
export EXTERNAL_IP=
```
---
</details>
</details>
7. Sent a request that will generate log data. In the OCI Cloud Shell terminal type.
```bash
curl -i -k -X GET -u jack:password https://store.$EXTERNAL_IP.nip.io/store/stocklevel
```
```
HTTP/1.1 200 OK
Server: nginx/1.17.8
Date: Thu, 23 Apr 2020 18:38:50 GMT
Content-Type: application/json
Content-Length: 149
Connection: keep-alive
Strict-Transport-Security: max-age=15724800; includeSubDomains
[{"itemCount":100,"itemName":"Book"},{"itemCount":50,"itemName":"Eraser"},{"itemCount":500,"itemName":"Pencil"},{"itemCount":5000,"itemName":"Pins"}]
```
Do this several times
If you get a DNS error that `store..nip.io` cannot be found this means that `EXTERNAL_IP` is not set, follow the instructions above to set it and then re-run the curl command.
## Task 4: The saved log files
Though the creation of the logs in the Object Storage Service is pretty cloud independent actually retrieving them is outside Kubernetes and specific to the cloud provider. The instructions below apply to the Oracle Object Storage Service.
Open the Object storage page on the OCI web console again and navigate to the bucket you created
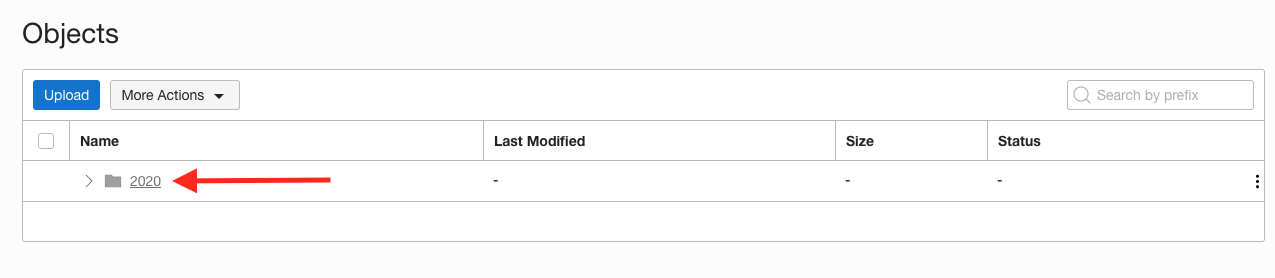
The Object storage UI provides a pseudo directory structure view. In this case there's only one "directory"
1. Click on the year
2. Continue navigating down the pseudo directory structure until you get to the objects created today
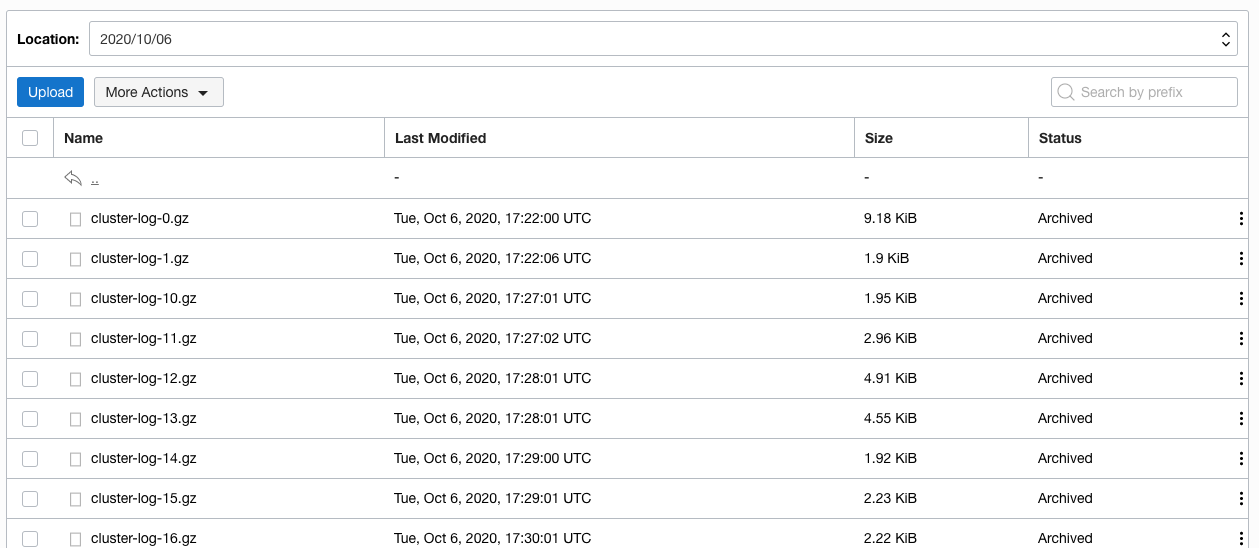
You can see the list of logs that have been saved. Note that all of them have a status of `Archived`.
If you can't see the list of files and fluentd has been running for a while try clicking on the **More Actions** button, then **Refresh**
Let's start the process to restore from the archive.
3. Click the selection checkbox next to **one** of the entries. Then click the **More Actions** button and chose **Restore** from the menu
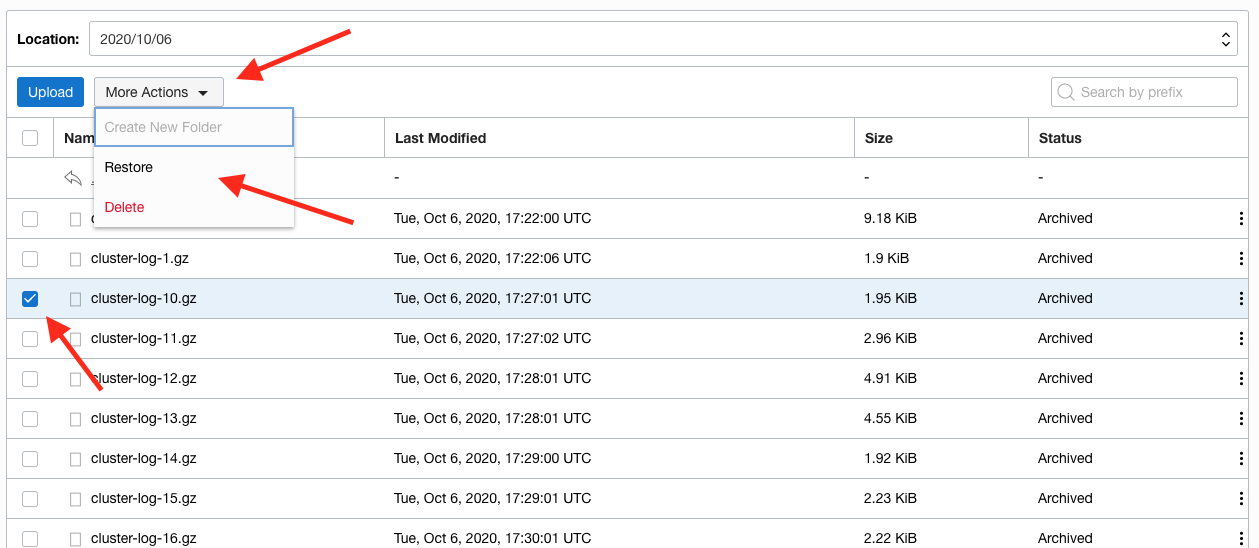
Note that the **Restore** and **Delete** buttons are now enabled.
4. Click the **Restore** button, the confirm restore popup is shown
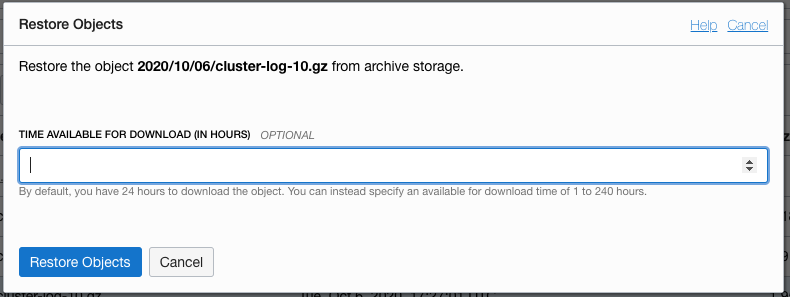
By default the restored data is available for 24 hours before it's only available in the archive again, you can change this duration if you like, but for now we'll leave the field blank which keeps the default 24 hours download window. The storage service will be charging you the extra copy for the time it's spent online, so you want to keep that to a minimum that meets your needs
5. Click the **Restore** button in the popup and the object storage service will trigger the restore process to start.
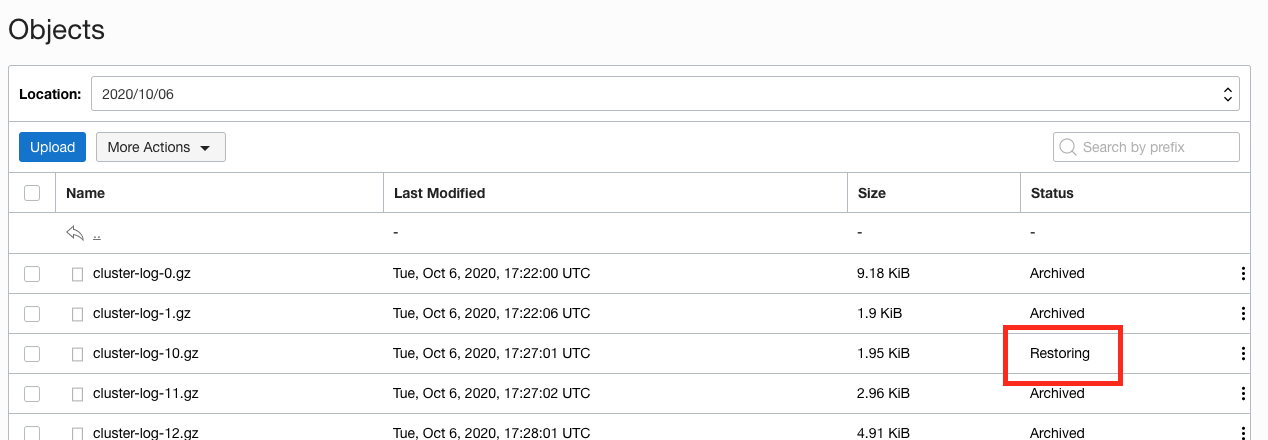
You can see that the status is now `Restoring`. Of course there is also a REST API to allow you to automate this process if you wanted in a production environment.
It can take several hours for the restore process to complete, especially if you chose multiple objects (remember we chose **Archive** as the storage tier as we wanted to show how to do long term cost effective storage of log data, and the archive tier is far more cost effective compared to the **Standard** tier, but the balance of that is the time to restore if you need to access the data.
If you want to progress with the lab then you can do so and come back to this section later to look at the restored data.
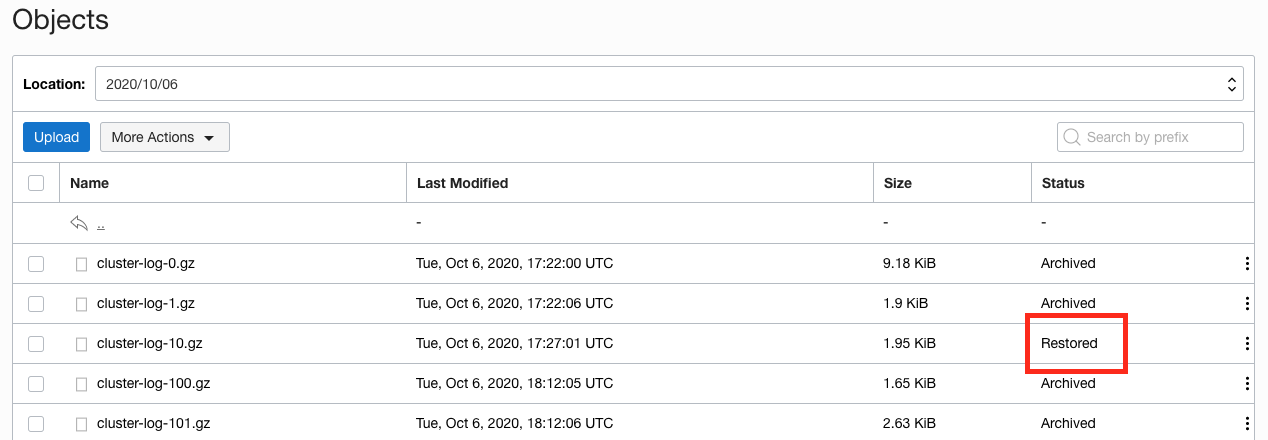
Once the restore process has completed you will see that the objects state becomes `Restored` (The images below were taken about an hour after starting the restore process). If you don't want to wait for the restore to complete just look at the images below to see what can be done, then follow the instructions in the **Tidying up the environment** section.
6. Click the three vertical dots just to the right of the word Restored to get the object menu.
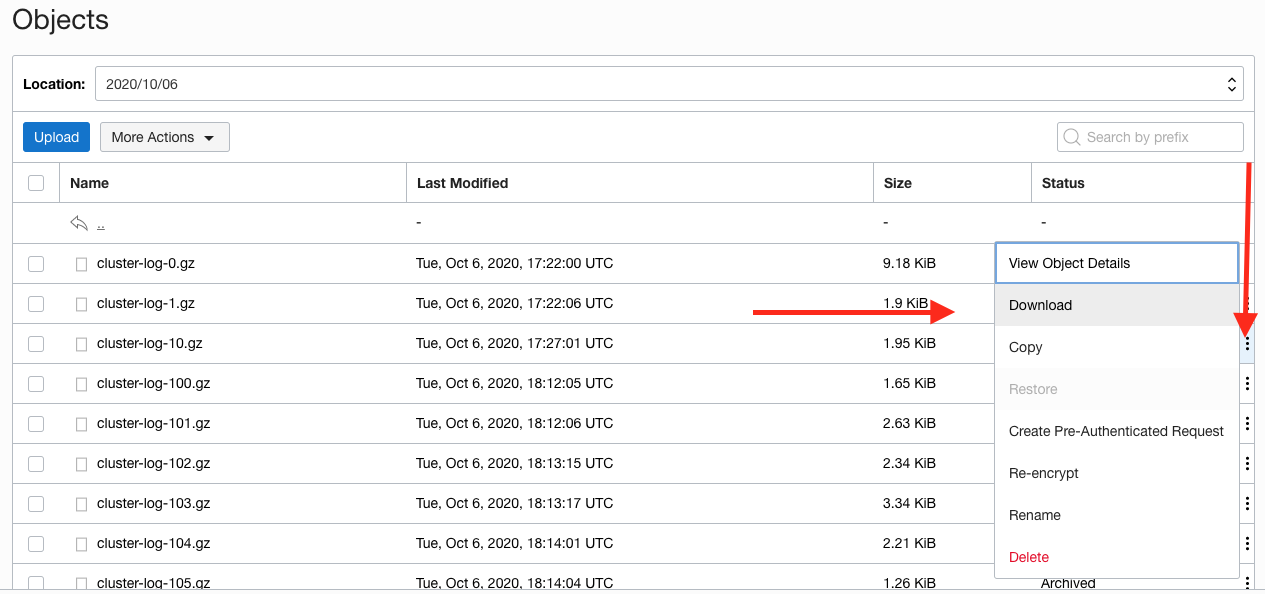
7. Click the **Download** option on this menu
Your web browser will start to download the object and depending on the web browser you will get a download options popup. This is the one I got when doing a similar download using Firefox on MacOS Catalina
To access the restored object follow whatever the normal procedure is on your computer to access a downloaded `.gz` file.
## Task 5: Tidying up the environment
If you are in a trial tenancy there are limitations on how many resources you can have in use at any time, and you may need them for other modules. The simplest way to release the resources used in his module (including the load balancer) is to delete the entire namespace.
If you want to leave the log capture running to see more of the data please feel free to do so (this particular module only generates storage objects) but do remember that this is consuming processing and storage resources. If you don't want to keep those tasks running the simplest way to stop all of the log capture activities is to delete the entire `logging` namespace.
1. To delete the `logging` namespace (if you have chosen to do this). In the OCI Cloud Shell type
```bash
kubectl delete namespace logging
```
```
namespace "logging" deleted
```
This may take a short time as there is quite a lot of stuff to be stopped and removed form the Kubernetes cluster.
Note that this will **not** reclaim the Object storage space used as the Object storage service is outside the Kubernetes environment.
To reclaim the Object storage capacity used