🧪 Testbed
Details
Generating a Test Dataset of Q&A pairs using an external LLM can significantly accelerate the testing phase. The Oracle AI Optimizer and Toolkit (the AI Optimizer) integrates with the Giskard framework, which is specifically designed to support this process.
Giskard analyzes documents to identify high-level topics associated with the generated Q&A pairs and automatically includes this information in the resulting Test Dataset. All test datasets and evaluation results are stored in the database, enabling future evaluations, comparisons, and reviews.
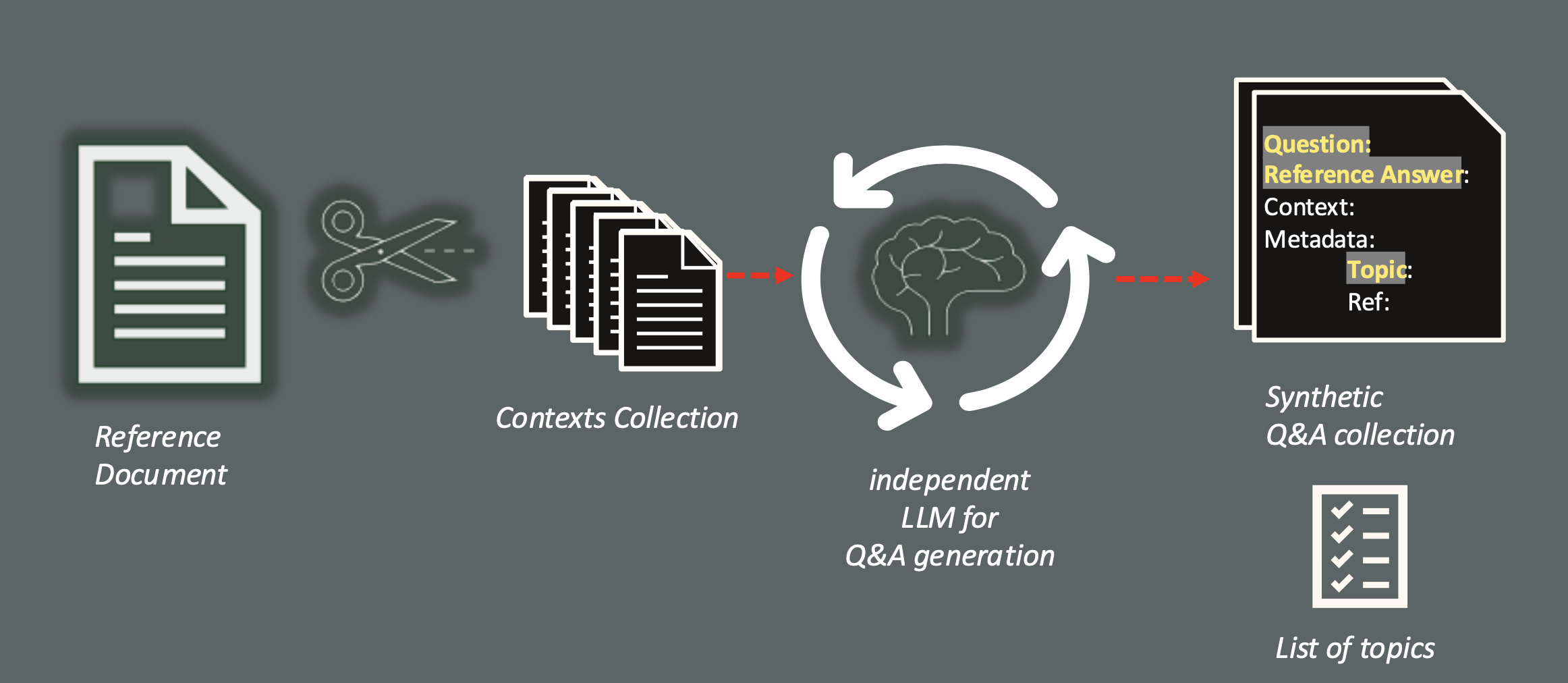
The dataset generation phase is optional but strongly recommended, especially during early evaluations. Manually creating high-quality test datasets requires substantial human effort, whereas automated generation reduces both time and cost.
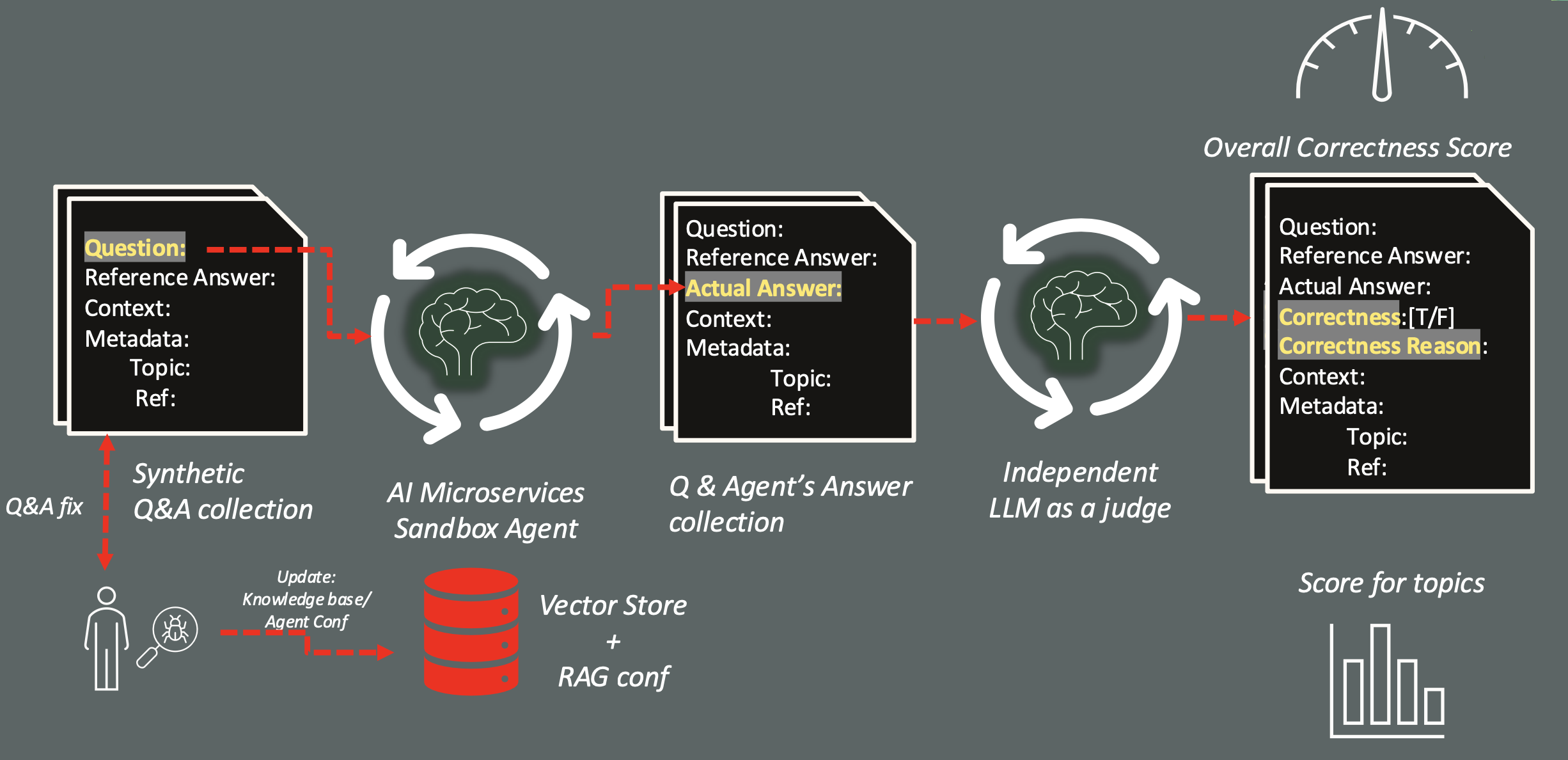
After the dataset is generated, each question is submitted to the configured agent. The agent’s responses are collected and compared against the expected answers by an LLM acting as an automated judge. The judge evaluates each response for semantic correctness and provides a justification for its decision, as illustrated in the following diagram:
Generation
From the Testbed page, switch to Generate Q&A Test Set and upload one or more documents. These documents will be embedded and analyzed by the selected Q&A Language/Embedding Models to generate a defined number of Q&A:
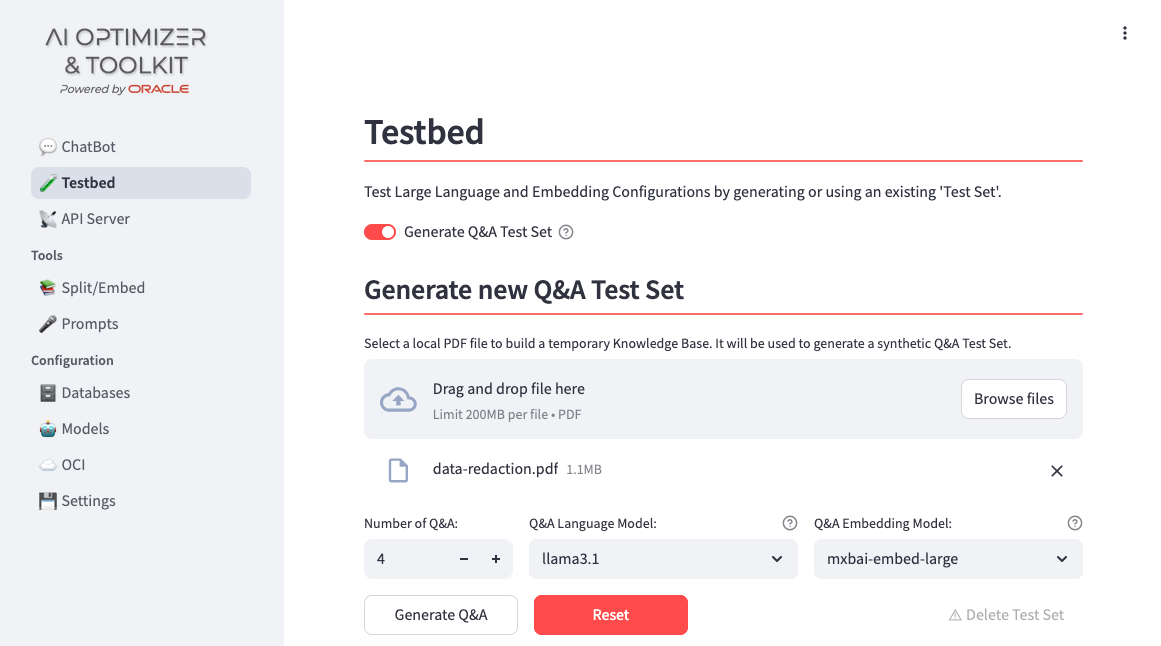
You can select any of the available models for the Q&A generation process. In many scenarios, it is useful to rely on a high-capability, higher-cost model to generate a high-quality evaluation dataset, while deploying a more cost-effective model in production.
This phase not only generates the number of Q&A you need, but it will analyze the documents provided extracting a set of topics that could help to classify the questions generated and can help to find the area to be improved.
Once the generation process is complete (which may take some time), the generated dataset is displayed:
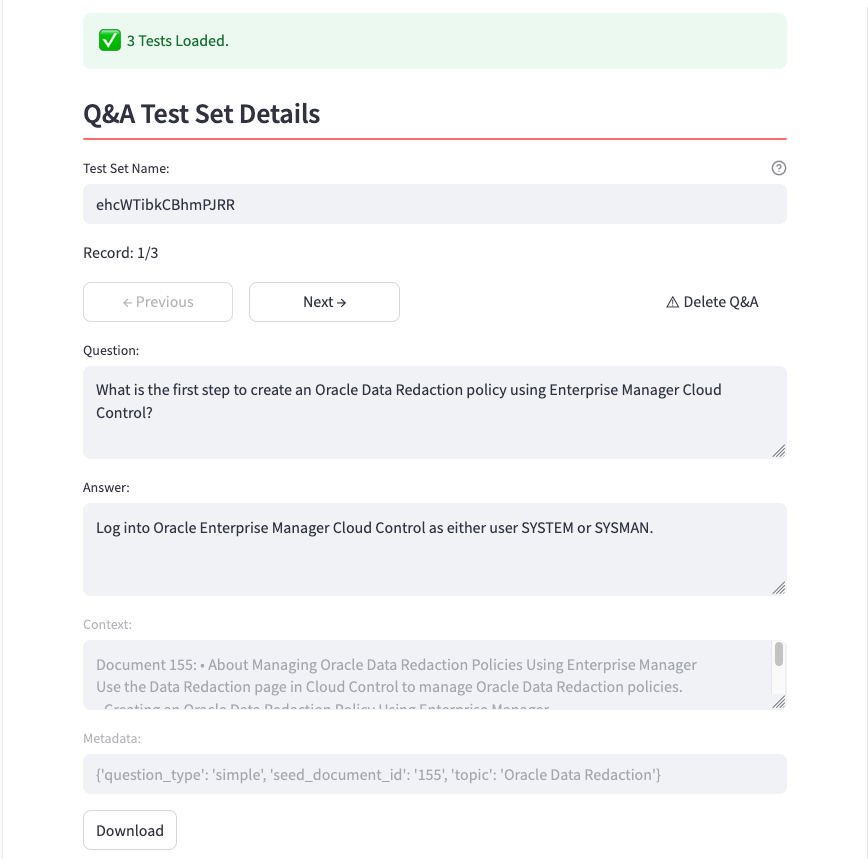
At this stage, you can:
- Delete a Q&A: clicking Delete Q&A you’ll drop the question from the final dataset if you consider it not meaningful;
- Modify the text of the Question and the Reference answer: if you are not agree, you can updated the raw text generated, according the Reference context that is it fixed, like the Metadata.
All changes are automatically stored in the database, and the dataset can also be downloaded for offline use.
The generation process is optional. If you have prepared a JSONL file with your Q&A, according to this schema:
You can upload it:
If you need an example, you can generate a single Q&A pair, download it, and use it as a template to extend your own Q&A test dataset.
Evaluation
At this point, if you have generated or are using an existing Test Dataset, you can run an evaluation using the configuration parameters in the left-hand side menu. Starting an evaluation will automatically save the Test Set to the database.

The upper section of the configuration menu is related to the LLM to be used for chat generation, and includes the most relevant hyper-parameters to use in the request. You can choose to enable the Store Discovery tool to perform AutoRAG, or disable it and manually select a specific Vector Store for the evaluation.
If you decide to target a specific Vector Store, it can be selected from the dropdown menu in the lower part of the left-hand side. Apart from the Embedding Model, Chunk Size, Chunk Overlap and Distance Strategy, that are fixed and determined during the Split/Embed process, these parameters can be adjusted:
- Top K: the number of document chunks included in the prompt context, selected based on their proximity to the question;
- Search Type: either Similarity or Maximal Marginal Relevance (MMR). Similarity search is commonly used, while MMR leverages an Oracle AI Database feature that reduces redundancy by excluding highly similar chunks and promoting more diverse yet relevant content.
Judge Model and Prompt
The evaluation requires selecting a Judge Language Model that acts as an automated evaluator. The judge compares each agent response against the reference answer and determines correctness based on semantic equivalence – the agent’s answer does not need to use the same wording as the reference, but it must convey the same meaning.
The judge’s behavior is controlled by the Testbed Judge Prompt, which can be customized through the Prompts configuration page. Adjusting this prompt allows you to fine-tune the evaluation strictness – for example, requiring more precise answers or allowing broader interpretations.
Results
An Overall Correctness Score will be provided at the end of the evaluation, that is simply the percentage of correct answers on the total number of questions submitted:
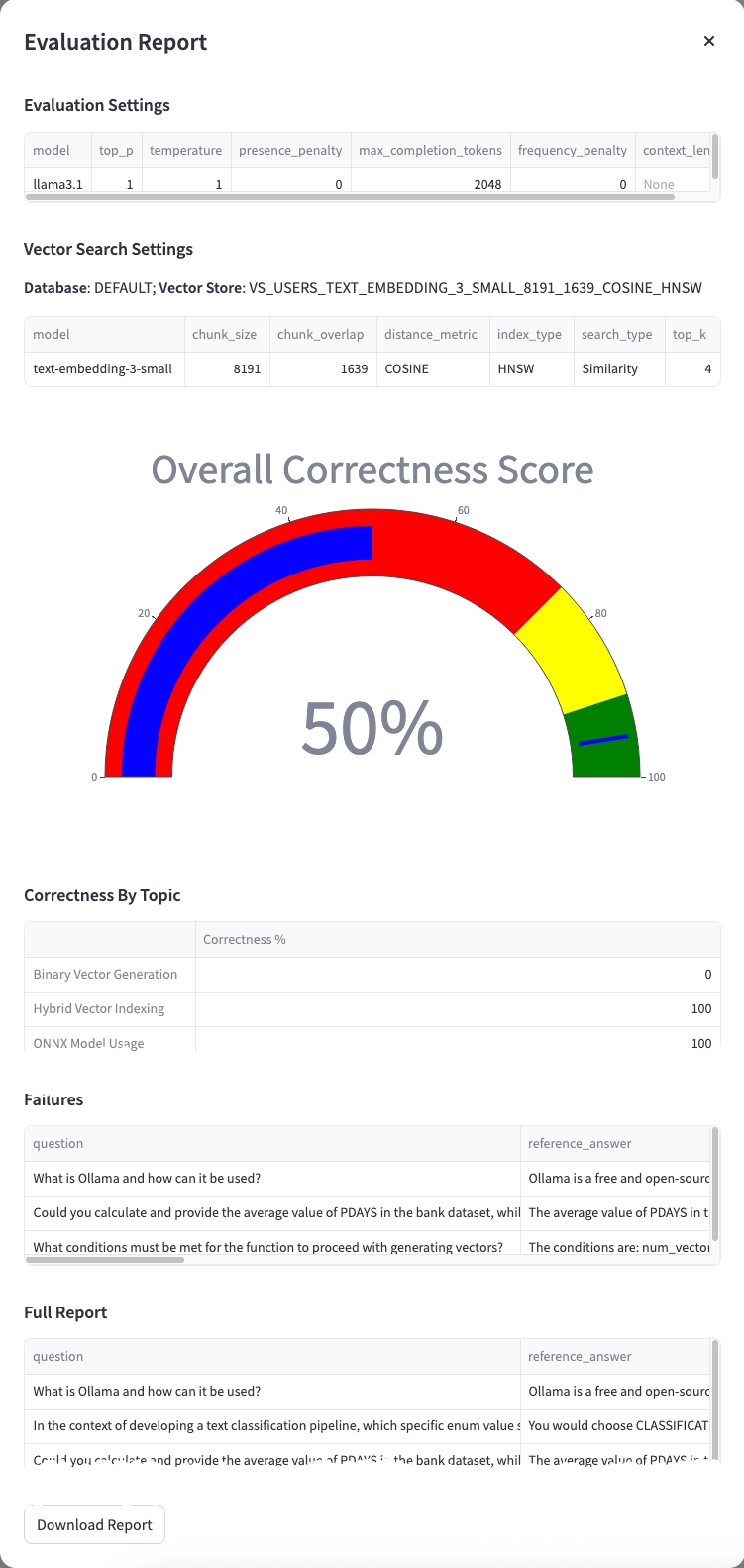
In addition, the evaluation produces correctness metrics grouped by topic, a detailed list of failures, and a complete breakdown of all evaluated Q&A pairs. For each Q&A in the test dataset, the following fields are added:
- agent_answer: the actual answer provided by the RAG app;
- correctness: true/false indicating whether the agent’s answer is semantically equivalent to the reference answer, as determined by the judge;
- correctness_reason: the reason why an answer has been evaluated wrong by the judge LLM.
The list of Failures, Correctness by each Q&A, as well as a Report, can be downloaded and stored for future review and audit purposes.
Previous Evaluations
All evaluation results are persisted in the database. When viewing a Test Set that has been previously evaluated, a Previous Evaluations dropdown is displayed, allowing you to select and review any past evaluation report. This makes it easy to compare results across different configurations or repeated runs.
Score Variability
Because the evaluation uses your configured hyper-parameters (including temperature), scores may vary slightly between runs. This is expected behavior and reflects the natural variability of your production configuration. Running multiple evaluations and comparing results provides a more reliable assessment of your RAG configuration’s effectiveness.
This approach enables repeated evaluations using the same curated test dataset, whether generated automatically or provided manually, to identify and validate the most effective RAG configuration.